




本文在上一篇文章(vectorbt学习_17DMA之三滑窗网格参数优选)面临问题
时间切分后,根据切分后的行情数据,重新计算技术指标,会存在一部分行情作为技术指标的预热时间被消耗掉。
比如:训练集,验证集时间(80,40), slow_windows=30,慢均线需要30天才有有效值。
则意味着训练集需要只有50(80-30)天,预测集10(40-30)天,技术指标slow_ma有有效取值。实际训练,验证集为(50,10),与本意偏差较大。
勘误:此篇文章部分截图可能有误,此文章的后继文章“DMA之六滑窗网格参数优选”修复此问题。请查阅后文。
01,基础配置信息
#conda envs:vectorbt_envimport warningsimport vectorbt as vbtimport numpy as npimport pandas as pdfrom datetime import datetime, timedeltaimport pytzfrom dateutil.parser import parseimport ipywidgets as widgetsfrom copy import deepcopyfrom tqdm import tqdmimport imageiofrom IPython import displayimport plotly.graph_objects as goimport itertoolsimport dateparserimport gcimport mathfrom tools import dbtools
warnings.filterwarnings("ignore")
pd.set_option('display.max_rows',500)pd.set_option('display.max_columns',500)pd.set_option('display.width',1000)02,行情获取和可视化
a,时间交易参数配置
# Enter your parameters hereseed = 42symbol = '002594.XSHE'metric = 'total_return'
start_date = datetime(2020, 1, 1, tzinfo=pytz.utc) # time period for analysis, must be timezone-awareend_date = datetime(2023,1,1, tzinfo=pytz.utc)time_buffer = timedelta(days=100) # buffer before to pre-calculate SMA/EMA, best to set to max windowfreq = '1D'
vbt.settings.portfolio['init_cash'] = 10000. # 100$vbt.settings.portfolio['fees'] = 0.0025 # 0.25%vbt.settings.portfolio['slippage'] = 0.0025 # 0.25%b,获取行情和行情mask
# Download data with time buffercols = ['Open', 'High', 'Low', 'Close', 'Volume']# ohlcv_wbuf = vbt.YFData.download(symbol, start=start_date-time_buffer, end=end_date).get(cols)
ohlcv_wbuf=dbtools.MySQLData.download(symbol).get() # 自带工具类查询assert(~ohlcv_wbuf.empty)ohlcv_wbuf = ohlcv_wbuf.astype(np.float64)
print("origin ohlcv_wbuf size:",ohlcv_wbuf.shape)print(ohlcv_wbuf.columns)
# Create a copy of data without time bufferwobuf_mask = (ohlcv_wbuf.index >= start_date) & (ohlcv_wbuf.index <= end_date) # mask without buffer
ohlcv = ohlcv_wbuf.loc[wobuf_mask, :]
print("wobuf_mask ohlcv size:",ohlcv.shape)
# Plot the OHLC dataohlcv.vbt.ohlcv.plot().show_svg() # 绘制蜡烛图# remove show_svg() to display interactive chart!origin ohlcv_wbuf size: (978, 5)Index(['Open', 'High', 'Low', 'Close', 'Volume'], dtype='object')wobuf_mask ohlcv size: (728, 5)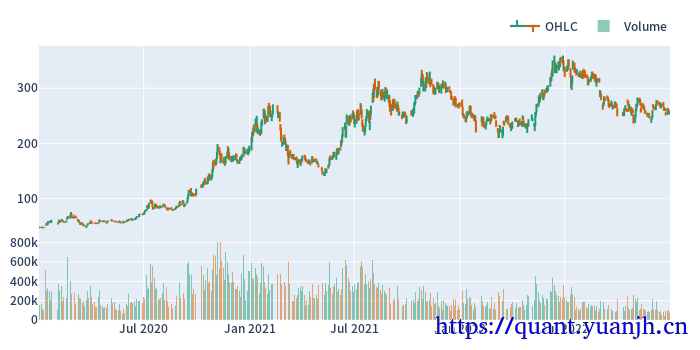
20,网格参数-指标计算和可视化
仅可视化第一列
price=ohlcv_wbuf['Close']windows = np.arange(10, 50)
fast_ma, slow_ma = vbt.MA.run_combs(price, windows, r=2, short_names=['fast', 'slow'])
print(fast_ma.ma.shape)print(slow_ma.ma.shape)
# Remove time bufferfast_ma = fast_ma[wobuf_mask]slow_ma = slow_ma[wobuf_mask]
# there should be no nans after removing time bufferassert(~fast_ma.ma.isnull().any().any())assert(~slow_ma.ma.isnull().any().any())
print(fast_ma.ma.shape)print(slow_ma.ma.shape)
fig = ohlcv['Close'].vbt.plot(trace_kwargs=dict(name='Price'))fig = fast_ma.ma.iloc[:,0].vbt.plot(trace_kwargs=dict(name="Fast MA col %d"%fast_ma.ma.iloc[:,0].name), fig=fig)fig = slow_ma.ma.iloc[:,0].vbt.plot(trace_kwargs=dict(name="Slow MA col %d"%slow_ma.ma.iloc[:,0].name), fig=fig)fig.show_svg()(978, 780)(978, 780)(728, 780)(728, 780)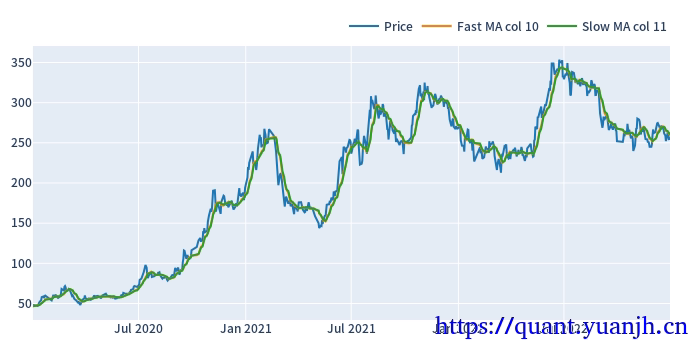
21,网格参数-信号计算和可视化
仅可视化第一列
dmac_size.shape: (728, 780)dmac_size.iloc[:3,:3]:fast_window 10slow_window 11 12 13date2020-01-02 00:00:00+00:00 True True True2020-01-03 00:00:00+00:00 True True True2020-01-06 00:00:00+00:00 True True True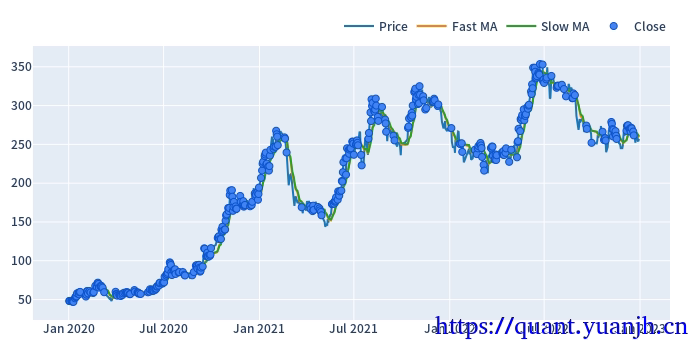
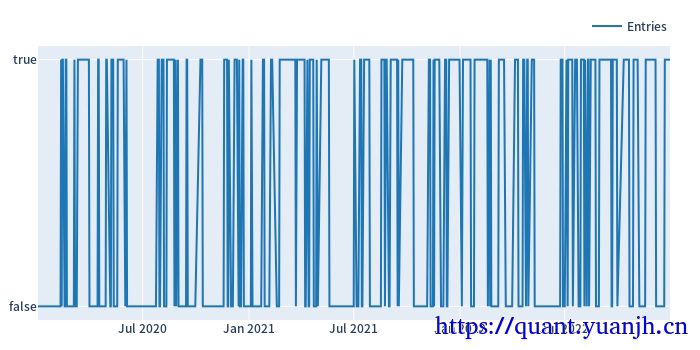
Start 2020-01-02 00:00:00+00:00End 2022-12-30 00:00:00+00:00Period 728Total 423.078205Rate [%] 58.115138First Index 2020-01-02 02:00:00+00:00Last Index 2022-12-27 06:59:04.615384576+00:00Norm Avg Index [-1, 1] -0.179136Distance: Min 1.0Distance: Max 75.946154Distance: Mean 1.720602Distance: Std 5.889353Total Partitions 14.607692Partition Rate [%] 3.501842Partition Length: Min 3.239744Partition Length: Max 85.138462Partition Length: Mean 36.392118Partition Length: Std 27.476308Partition Distance: Min 4.425641Partition Distance: Max 75.946154Partition Distance: Mean 29.174564Partition Distance: Std 26.152924Name: agg_func_mean, dtype: object22,行情,信号的滑窗处理
注意点:
01,训练集和验证集比例3:1,或者2:1,对应:window_len和set_lens为4<1>(或3<1>),过大了历史包袱沉重,无法及时响应最新行情,过小了则容易参数跳变,形成类似过拟合效果
a,参数设置和效果预览
代码中
# todo这里是自然日计算的,但后面训练,验证集个数计算都完全正确,哪里应该和预想的不一致合理的。实测bar_days= 60时
print(in_indexes[0][0])print(in_indexes[1][0])print(in_indexes[0][53:55])
2019-01-02 00:00:00+00:002019-03-25 00:00:00+00:00DatetimeIndex(['2019-03-25 00:00:00+00:00', '2019-03-26 00:00:00+00:00'], dtype='datetime64[ns, UTC]', name='split_0', freq=None)可见第二行第一个位于第一行第53个,不足设置的60,就是由于切分优先保证了数据的足量,但是数据间隔方面则可能有所重叠。# 滚动周期参数设置和大致效果可视化start_end_days=int((end_date-start_date).days) #todo 这里是自然日计算的,但后面训练,验证集个数计算都完全正确,哪里应该和预想的不一致bar_days= 80 # 训练,验证集时间长度,以此为单位test_bar_num=2 # 训练集时间长度verify_bar_num=1 # 验证集时间长度verify_overlap=0 # 验证集重叠时间长度pre_test_days=0 # 由于测试集一部分时间用于计算指标,导致实际训练时间不足,这个是一定程度补充的days周期# n取值需要满足:确保验证集合收尾相接# => (n-1)*(verify_bar_num-verify_overlap)+(verify_bar_num+test_bar_num)=start_end_days/bar_days# => n=(start_end_days/bar_days-test_bar_num-verify_overlap)/(verify_bar_num-verify_overlap)calc_n=(start_end_days/bar_days-test_bar_num-verify_overlap)/(verify_bar_num-verify_overlap)
split_kwargs = dict( n=int(calc_n), window_len=int(bar_days*(test_bar_num+verify_bar_num)+pre_test_days), set_lens=(int(bar_days*verify_bar_num),), left_to_right=False) # 10 windows, each 2 years long, reserve 180 days for test# 合理设置n,最好确保验证集,连续且无重复pf_kwargs = dict( direction='both', # long and short freq='d')print('split_kwargs:',split_kwargs)
def roll_in_and_out_samples(price, **kwargs): return price.vbt.rolling_split(**kwargs)
# 验证:单列数据验证,橘黄色验证集连续且无重复roll_in_and_out_samples(price, **split_kwargs, plot=True, trace_names=['in-sample', 'out-sample']).show_svg()
# 大致观察数据特征(in_price, in_indexes), (out_price, out_indexes) = roll_in_and_out_samples(price, **split_kwargs)
print('in_price.shape:',in_price.shape ) # in-sampleprint('out_price.shape:',out_price.shape)print('in_price.index:',in_price.index)print('in_price.columns:',in_price.columns)print('in_price[0:3]:',in_price[0:3])
print('in_indexes[:5]:',in_indexes[:3])split_kwargs: {'n': 11, 'window_len': 240, 'set_lens': (80,), 'left_to_right': False}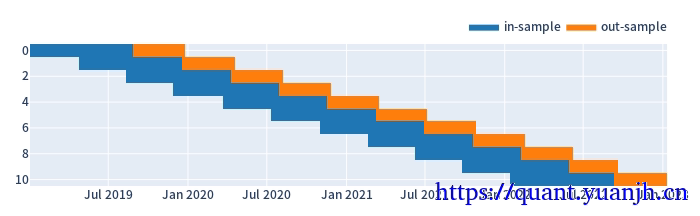
in_price.shape: (160, 11)out_price.shape: (80, 11)in_price.index: RangeIndex(start=0, stop=160, step=1)in_price.columns: Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype='int64', name='split_idx')in_price[0:3]: split_idx 0 1 2 3 4 5 6 7 8 9 100 49.17 58.15 51.20 43.39 48.15 97.90 167.98 239.52 202.00 251.77 253.141 48.06 56.16 49.50 43.15 49.73 96.55 164.08 225.00 214.11 252.50 266.492 50.65 55.36 50.29 43.79 52.25 94.50 168.03 208.99 227.02 246.86 266.08in_indexes[:5]: [DatetimeIndex(['2019-01-02 00:00:00+00:00', '2019-01-03 00:00:00+00:00', '2019-01-04 00:00:00+00:00', '2019-01-07 00:00:00+00:00', '2019-01-08 00:00:00+00:00', '2019-01-09 00:00:00+00:00', '2019-01-10 00:00:00+00:00', '2019-01-11 00:00:00+00:00', '2019-01-14 00:00:00+00:00', '2019-01-15 00:00:00+00:00', ... '2019-08-14 00:00:00+00:00', '2019-08-15 00:00:00+00:00', '2019-08-16 00:00:00+00:00', '2019-08-19 00:00:00+00:00', '2019-08-20 00:00:00+00:00', '2019-08-21 00:00:00+00:00', '2019-08-22 00:00:00+00:00', '2019-08-23 00:00:00+00:00', '2019-08-26 00:00:00+00:00', '2019-08-27 00:00:00+00:00'], dtype='datetime64[ns, UTC]', name='split_0', length=160, freq=None), DatetimeIndex(['2019-04-24 00:00:00+00:00', '2019-04-25 00:00:00+00:00', '2019-04-26 00:00:00+00:00', '2019-04-29 00:00:00+00:00', '2019-04-30 00:00:00+00:00', '2019-05-06 00:00:00+00:00', '2019-05-07 00:00:00+00:00', '2019-05-08 00:00:00+00:00', '2019-05-09 00:00:00+00:00', '2019-05-10 00:00:00+00:00', ... '2019-12-04 00:00:00+00:00', '2019-12-05 00:00:00+00:00', '2019-12-06 00:00:00+00:00', '2019-12-09 00:00:00+00:00', '2019-12-10 00:00:00+00:00', '2019-12-11 00:00:00+00:00', '2019-12-12 00:00:00+00:00', '2019-12-13 00:00:00+00:00', '2019-12-16 00:00:00+00:00', '2019-12-17 00:00:00+00:00'], dtype='datetime64[ns, UTC]', name='split_1', length=160, freq=None), DatetimeIndex(['2019-08-12 00:00:00+00:00', '2019-08-13 00:00:00+00:00', '2019-08-14 00:00:00+00:00', '2019-08-15 00:00:00+00:00', '2019-08-16 00:00:00+00:00', '2019-08-19 00:00:00+00:00', '2019-08-20 00:00:00+00:00', '2019-08-21 00:00:00+00:00', '2019-08-22 00:00:00+00:00', '2019-08-23 00:00:00+00:00', ... '2020-03-26 00:00:00+00:00', '2020-03-27 00:00:00+00:00', '2020-03-30 00:00:00+00:00', '2020-03-31 00:00:00+00:00', '2020-04-01 00:00:00+00:00', '2020-04-02 00:00:00+00:00', '2020-04-03 00:00:00+00:00', '2020-04-07 00:00:00+00:00', '2020-04-08 00:00:00+00:00', '2020-04-09 00:00:00+00:00'], dtype='datetime64[ns, UTC]', name='split_2', length=160, freq=None)]b,根据滑窗参数切分行情数据和信号
(in_price, in_indexes), (out_price, out_indexes) = roll_in_and_out_samples(price, **split_kwargs)
print('in_price.shape:',in_price.shape ) # in-sampleprint('out_price.shape:',out_price.shape)
print(in_indexes[0][0])print(in_indexes[1][0])print(in_indexes[0][53:55])
print("###################")
(in_dmac_size,in_dmac_size_indexes),(out_dmac_size,out_dmac_size_indexes) = roll_in_and_out_samples(dmac_size, **split_kwargs)
print('in_dmac_size.shape:',in_dmac_size.shape)print('in_dmac_size.iloc[:5,:5]:')print(in_dmac_size.iloc[:5,:5])in_price.shape: (160, 11)out_price.shape: (80, 11)2019-01-02 00:00:00+00:002019-04-24 00:00:00+00:00DatetimeIndex(['2019-03-25 00:00:00+00:00', '2019-03-26 00:00:00+00:00'], dtype='datetime64[ns, UTC]', name='split_0', freq=None)###################in_dmac_size.shape: (160, 8580)in_dmac_size.iloc[:5,:5]:split_idx 0fast_window 10slow_window 11 12 13 14 150 True True True True True1 True True True True True2 True True True True True3 True True True True True4 True True True True True23,滑窗的收益数据计算
a,持有参数收益
在此区间,基础标的物表现
def simulate_holding(price, **kwargs): pf = vbt.Portfolio.from_holding(price, **kwargs) return pf.sharpe_ratio()
in_hold_sharpe = simulate_holding(in_price, **pf_kwargs)print(in_hold_sharpe.head(5))
out_hold_sharpe = simulate_holding(out_price, **pf_kwargs)print(out_hold_sharpe.head(5))split_idx0 0.2354461 -1.6306162 0.5988893 2.6473974 4.501923Name: sharpe_ratio, dtype: float64split_idx0 -0.9299561 2.0659912 4.1003003 4.8012914 0.688785Name: sharpe_ratio, dtype: float64b,网格参数收益(训练集和验证集)
(8580,)fast_window slow_window split_idx10 11 0 0.235446 12 0 0.235446 13 0 0.235446 14 0 0.235446 15 0 0.235446 ...46 48 10 1.161184 49 10 1.32557247 48 10 1.088731 49 10 1.12922448 49 10 0.958552Name: sharpe_ratio, Length: 8580, dtype: float64(8580,)fast_window slow_window split_idx10 11 0 -0.703309 12 0 -0.703309 13 0 -0.703309 14 0 -0.929956 15 0 -0.929956 ...46 48 10 -0.119443 49 10 0.51615247 48 10 -0.119443 49 10 -0.16092248 49 10 -0.160922Name: sharpe_ratio, Length: 8580, dtype: float64c,训练集上的最佳参数用于验证集
大致思路:
01,获取各split_idx的最佳收益(sharp_radio)的参数组合idxmax,也就是fast_window,slow_window,split_idx,三维索引元组
02,按照split_idx进行聚类,取得各split_idx对应的最佳参数。实际含义就是各滑动窗口的最佳参数
def get_best_index(performance, higher_better=True): if higher_better: return performance[performance.groupby('split_idx').idxmax()].index return performance[performance.groupby('split_idx').idxmin()].indexin_best_index = get_best_index(in_sharpe)
print(in_best_index[:5])
def get_best_params(best_index, level_name): return best_index.get_level_values(level_name).to_numpy()in_best_fast_windows = get_best_params(in_best_index, 'fast_window')in_best_slow_windows = get_best_params(in_best_index, 'slow_window')in_best_window_pairs = np.array(list(zip(in_best_fast_windows, in_best_slow_windows)))
print(in_best_window_pairs[:5][:])pd.DataFrame(in_best_window_pairs, columns=['fast_window', 'slow_window']).vbt.plot().show_svg()MultiIndex([(35, 49, 0), (10, 30, 1), (10, 15, 2), (11, 15, 3), (10, 11, 4)], names=['fast_window', 'slow_window', 'split_idx'])[[35 49] [10 30] [10 15] [11 15] [10 11]]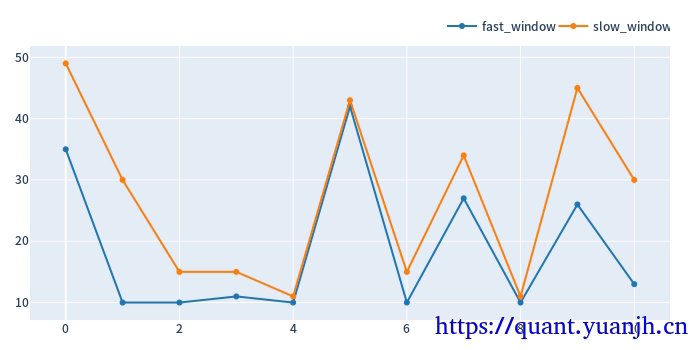
将滚动获取的最佳参数用于验证集,统计收益信息
print('out_dmac_size.shape:',out_dmac_size.shape)print('in_best_index.shape:',in_best_index.shape)print('in_best_index:',in_best_index)print('out_dmac_size.columns:',out_dmac_size.columns)# out_dmac_size[(0,10,12)]print('out_dmac_size.columns.names:',out_dmac_size.columns.names)print('in_best_index.names:',in_best_index.names)
# 调整 out_dmac_size 的列索引级别顺序,使其与 in_best_index 的级别顺序一致out_dmac_size_reindexed = out_dmac_size.swaplevel('split_idx', 'fast_window', axis=1).swaplevel('slow_window', 'split_idx', axis=1).sort_index(axis=1)# 使用调整后的列索引进行 iloc 操作# out_dmac_size_reindexed.columnsresult = out_dmac_size_reindexed[in_best_index]# out_dmac_size.iloc[in_best_index]
print('out_dmac_size_reindexed[in_best_index].shape:',out_dmac_size_reindexed[in_best_index].shape)
# out_dmac_size_reindexed[in_best_index].astype(np.int)out_dmac_size.shape: (80, 8580)in_best_index.shape: (11,)in_best_index: MultiIndex([(35, 49, 0), (10, 30, 1), (10, 15, 2), (11, 15, 3), (10, 11, 4), (42, 43, 5), (10, 15, 6), (27, 34, 7), (10, 11, 8), (26, 45, 9), (13, 30, 10)], names=['fast_window', 'slow_window', 'split_idx'])out_dmac_size.columns: MultiIndex([( 0, 10, 11), ( 0, 10, 12), ( 0, 10, 13), ( 0, 10, 14), ( 0, 10, 15), ( 0, 10, 16), ( 0, 10, 17), ( 0, 10, 18), ( 0, 10, 19), ( 0, 10, 20), ... (10, 45, 46), (10, 45, 47), (10, 45, 48), (10, 45, 49), (10, 46, 47), (10, 46, 48), (10, 46, 49), (10, 47, 48), (10, 47, 49), (10, 48, 49)], names=['split_idx', 'fast_window', 'slow_window'], length=8580)out_dmac_size.columns.names: ['split_idx', 'fast_window', 'slow_window']in_best_index.names: ['fast_window', 'slow_window', 'split_idx']out_dmac_size_reindexed[in_best_index].shape: (80, 11)
id col size entry_idx entry_price entry_fees exit_idx exit_price exit_fees pnl return direction status parent_id0 0 0 199.762836 0 49.934525 24.937656 79 46.85 0.0 -641.111119 -0.064271 0 0 01 1 1 222.599259 0 44.811750 24.937656 79 58.80 0.0 3088.836429 0.309656 0 0 12 2 2 182.338041 0 54.706425 24.937656 79 88.73 0.0 6178.854345 0.619430 0 0 23 3 3 114.462060 0 87.147325 24.937656 79 183.53 0.0 11007.221874 1.103474 0 0 34 4 4 59.581957 0 167.417500 24.937656 79 176.88 0.0 538.856616 0.054020 0 0 45 5 5 56.155465 0 177.632975 24.937656 79 250.50 0.0 4066.944030 0.407711 0 0 56 6 6 39.282222 0 253.933250 24.937656 79 321.74 0.0 2638.662163 0.264526 0 0 67 7 7 33.080178 35 301.541975 24.937656 79 240.60 0.0 -2040.909064 -0.204601 0 0 78 8 8 41.989226 0 237.562425 24.937656 79 314.89 0.0 3221.987364 0.323004 0 0 89 9 9 33.376449 0 298.865300 24.937656 79 274.21 0.0 -847.844011 -0.084996 0 0 910 10 10 39.143143 44 254.835500 24.937656 79 266.59 0.0 435.170415 0.043626 0 0 10fast_window slow_window split_idx35 49 0 -0.92995610 30 1 2.065991 15 2 4.10030011 15 3 4.80129110 11 4 0.688785Name: sharpe_ratio, dtype: float6424,sharp ratio的汇总可视化
cv_results_df = pd.DataFrame({ 'in_sample_hold': in_hold_sharpe.values, 'in_sample_median': in_sharpe.groupby('split_idx').median().values, 'in_sample_best': in_sharpe[in_best_index].values, 'out_sample_hold': out_hold_sharpe.values, 'out_sample_median': out_sharpe.groupby('split_idx').median().values, 'out_sample_test': out_test_sharpe.values})
color_schema = vbt.settings['plotting']['color_schema']
cv_results_df.vbt.plot( trace_kwargs=[ dict(line_color=color_schema['blue']), dict(line_color=color_schema['blue'], line_dash='dash'), dict(line_color=color_schema['blue'], line_dash='dot'), dict(line_color=color_schema['orange']), dict(line_color=color_schema['orange'], line_dash='dash'), dict(line_color=color_schema['orange'], line_dash='dot') ]).show_svg()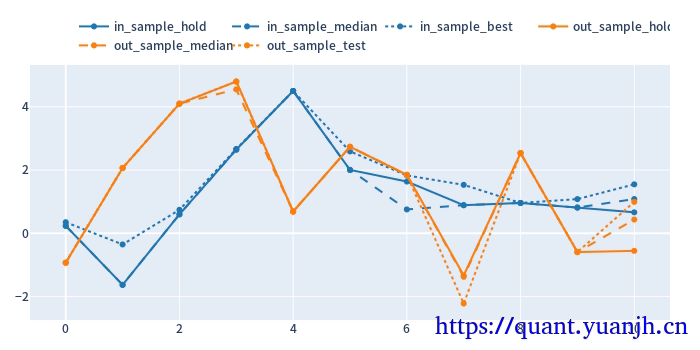
关注点:
蓝色部分 正常排序是(从上到下):点线,实现,线段,
橘色部分
实线对实线
说明测试集和验证集的周期收益情况,二者同时出现0轴同侧较好(同时上涨,同时下跌,保持行情的稳定性or延续性)
线段对线段
二者一方面随着各自颜色的实线趋势变化(受各自实线影响较大),其他应该无必然联系
点线对点线
蓝色点高于橘色点线,蓝色是训练集内最佳,橘色则是训练集得到最优参数用于验证集结果收益,大概率低于验证集。
测试,验证集时间长度差异,引入偏差
由于测试集一般是验证集的2-3倍(或更多),对于单边行情(假如上涨),则(测试集的)实线收益。蓝色线大概率位于橘色线上方。
如果下跌,则相反。蓝色由于时间长,大概率位于橘色下方。
注意: 01,202406,对于当前case,y周取值为sharp ratio夏普比,而非收益率。所以数据点高低并不反映收益率。 所以,以上结论需要稍斟酌,并不完全准确。
25,滚动回测收益可视化
# 验证集:原始价格变动out_price_org=out_price.iloc[-1, :]/out_price.iloc[0, :]print('out_price_org shape:',out_price_org.shape)print(out_price_org.head(5))
# 验证集:持有收益率def simulate_holding(price, **kwargs): pf = vbt.Portfolio.from_holding(price, **kwargs) return pf.total_return()
out_hold_return = simulate_holding(out_price, **pf_kwargs)print("############")print('out_hold_return shape:',out_hold_return.shape)print(out_hold_return.head(5))
print("############")print('out_test_return shape:',out_test_return.shape)print(out_test_return.head(5))
cv_results_df = pd.DataFrame({ 'out_price_org': out_price_org.cumprod(), 'out_hold_return': (out_hold_return.values+1).cumprod(), 'out_test_return': (out_test_return.values+1).cumprod()})
color_dmac_pfschema = vbt.settings['plotting']['color_schema']
cv_results_df.vbt.plot( trace_kwargs=[ dict(line_color=color_schema['blue']), dict(line_color=color_schema['blue'], line_dash='dash'), dict(line_color=color_schema['blue'], line_dash='dot') ]).show_svg()out_price_org shape: (11,)split_idx0 0.9405741 1.3154362 1.6259853 2.1112394 1.059162dtype: float64############out_hold_return shape: (11,)split_idx0 -0.0641111 0.3088842 0.6178853 1.1007224 0.053886Name: total_return, dtype: float64############out_test_return shape: (11,)fast_window slow_window split_idx35 49 0 -0.06411110 30 1 0.308884 15 2 0.61788511 15 3 1.10072210 11 4 0.053886Name: total_return, dtype: float64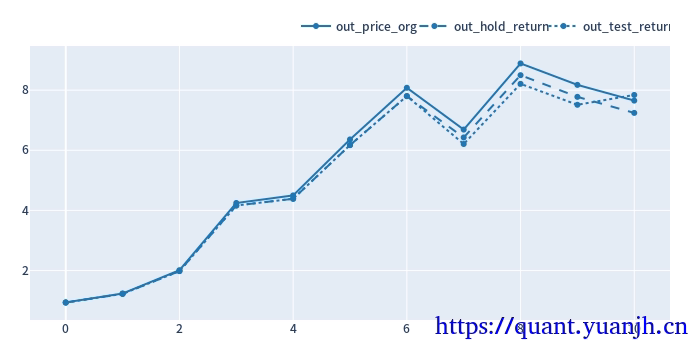
可见,整体结果尚可,上涨幅度基本吃到位,由于单纯依赖技术指标退出,没有止损。所以回撤也是无法避免的。
进一步思考
(非滚动模式)网格参数寻优得到的固定参数,其实是使用未来信息的(未来行情),不符合实际,也就是实际上无法落地。(5月份时,无法知道未来5-10月份,某个参数会取得较好收益)
滚动的网格参数寻优更符合实际,不含未来信息(可落地)。
时间周期越长,基于(非滚动模式)网格参数寻优取得较高收益概率越大,本质上是对历史的拟合。
但是滚动的测试未必,由于其未使用未来信息,如果策略本身无效,则大概率围绕0波动,类似随机。
26,计算正确性验证(略)
a,准备校验数据,数据展示b,行情->指标 计算正确02326222428c,指标->信号 计算正确d,信号->交易 计算正确部分信息可能已经过时