




阶段性回顾汇总之前个文章,步骤的核心功能。
DMA之一基础策略
通过2个vbt.MA.run计算均线,然后计算指标和可视化,计算信号和可视化,最终形成交易序列以及可视化。
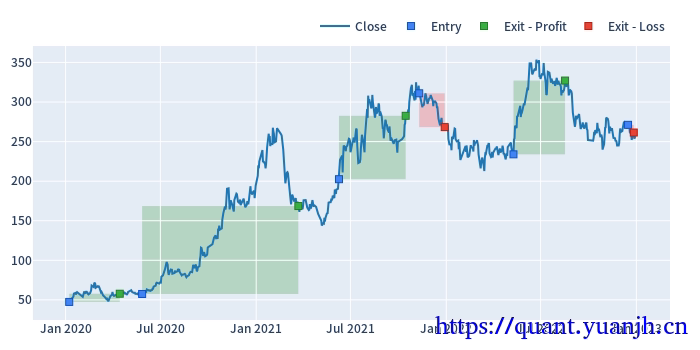
DMA之二网格参数优选
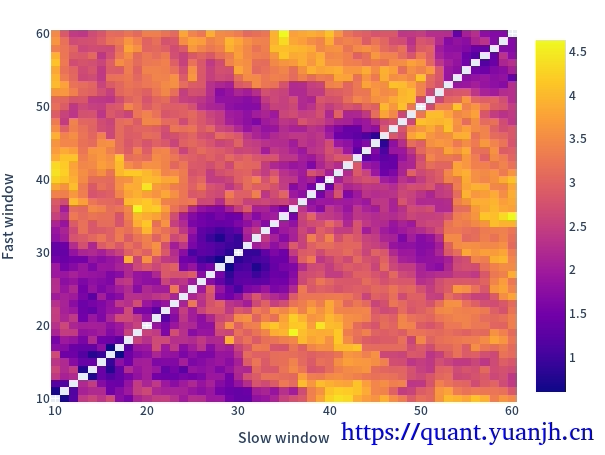
在上一篇基础上,使用vbt.MA.run_combs,形成多个参数组合的策略,网格遍历的形式优选出最佳均线参数。获得各参数表现热力图,以及最佳表现。
局限在于:
01,虽然回测但无法实盘,原因是对于今天来讲,使用的均是历史信息,但是对于过去视角看,过去是不知道未来xx月,使用xx参数可以取得较好收益。所以获得回测结果也就只能看看而已,不具备落地条件。
02,由于参数在整个测试区间都是固定,限制了策略表现,现实中参数大概率随时间or行情走势动态变动的。固定参数无法动态的适应行情。
DMA之三滑窗网格参数优选(滚动窗口)
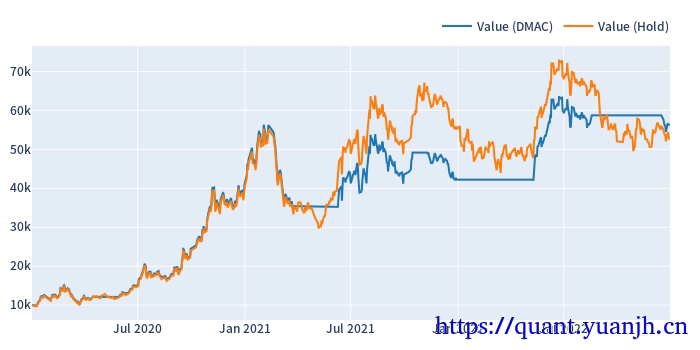
采用滚动窗口+网格参数优选,分析出动态最优参数。
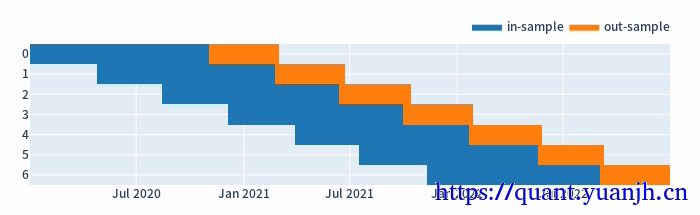
需要对行情,做滚动切分,切分成训练集,预测集
训练集用于测试各参数的表现,选择最优用于预测集合。同时也要尽可能保证
a,训练集和预测集数据比例合适.
b,预测集合尽可能首尾相接连续整合行情区间,避免重复或者间隙过多(重复或者间隙可能导致double/错过 某周期性行情,引入额外测试误差).
验证集的收益计算采用,会面临预热问题,导致验证集信号稀疏。也会破坏最初设计的验证集首尾相接接近整个时间区间。
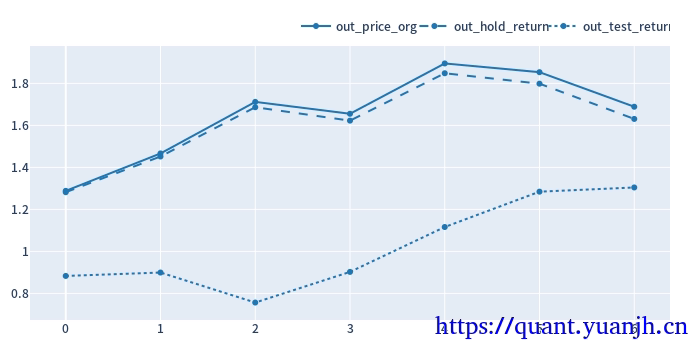
def simulate_all_params(price, windows, **kwargs): fast_ma, slow_ma = vbt.MA.run_combs(price, windows, r=2, short_names=['fast', 'slow']) entries = fast_ma.ma_crossed_above(slow_ma) exits = fast_ma.ma_crossed_below(slow_ma) pf = vbt.Portfolio.from_signals(price, entries, exits, **kwargs) return pf.sharpe_ratio()最终效果
DMA之四滑窗网格参数优选(size状态仓位)
处理预热问题,将信号,指标的计算前置,entry+exit机制改为状态机制(否则entry按照滚动周期,切分后会有信号丢失的问题)。
此时得到结果
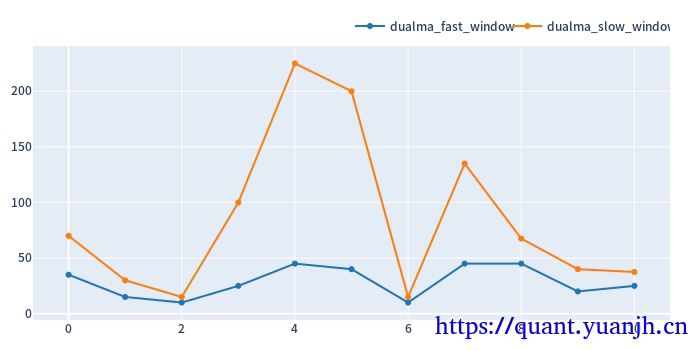
 对应到参数走势图
对应到参数走势图
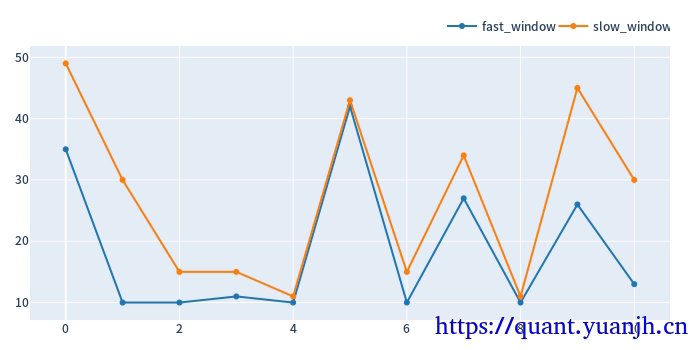
显然参数不合理,出现(10,11),(43,44)这种参数组合。
不过,这是第一个理论上没有未来数据等硬伤,且可持续滚动进行下去的版本。
DMA之五滑窗网格参数优选(参数正交性<快线>*慢线乘数)
改进了参数组合方式,采用快线以及慢线相对快线的倍率。大致认为剔除二者相关性了(正交性)。
此时就无法借助run_combs创建组合计算指标了,需基于vbt创建新技术指标DualMA
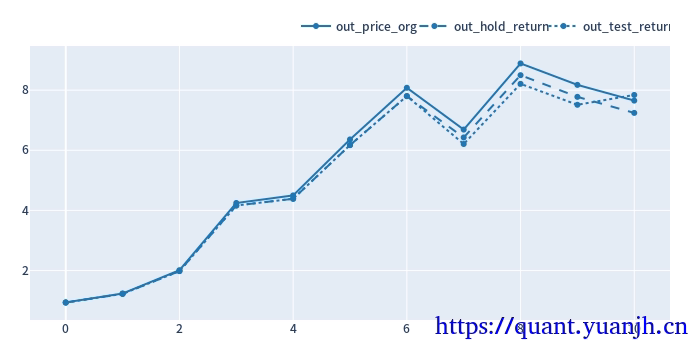
参数走势
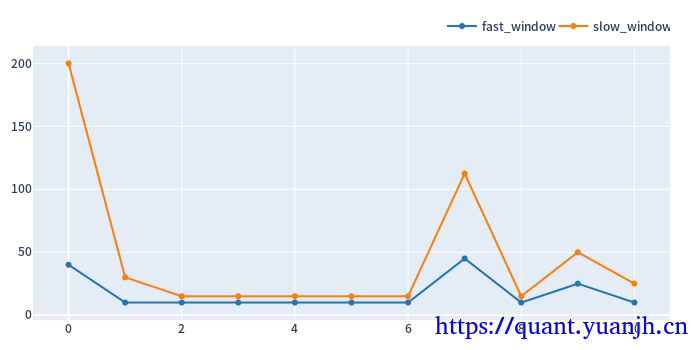
最终效果
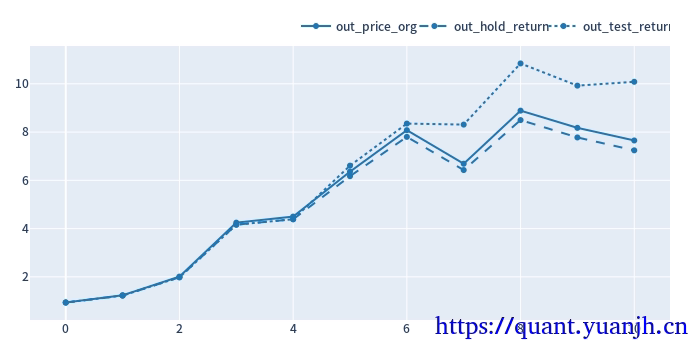
DMA之六滑窗网格参数优选(4种参数优选)
之前每个周期(训练集)的最佳参数,都是采用直接优选的方法。可能存在局部最优过拟合陷阱(某个参数效果很好,但是其邻居效果奇差)。新增3种参数优选方法,一定程度上降低参数过拟合的可能。
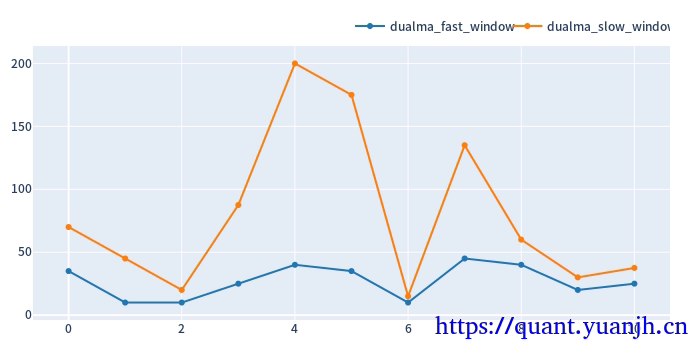
v1<直接>(简单最大值)优选法
选取,测试集合的最优参数作为验证集参数,如果sharp_ratio就最大,回撤就最小类似这样的简单优选策略。
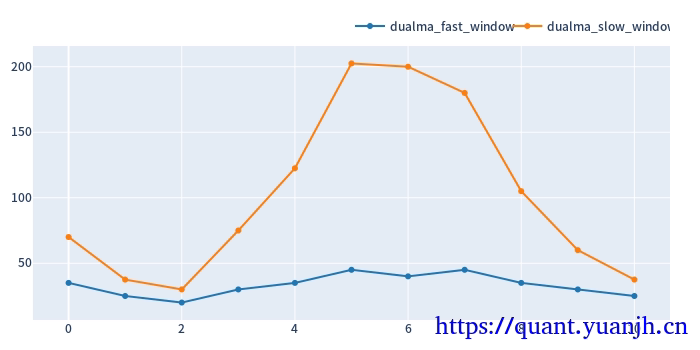
v2<邻近域优选法>
在上一个策略中,实际上是选取,测试集合的最优参数作为验证集参数。而有些情况下,测试集得到参数会突然发生较大变化,这可能偶发事件导致的,
比如:之前的双均线最佳参数一直是,(20,40),本期突然变成(80,160),显然不大合理,为了避免这种突变,让参数的变化也具有一定连贯性(当然,增加连贯性也一定程度降低过拟合风险)
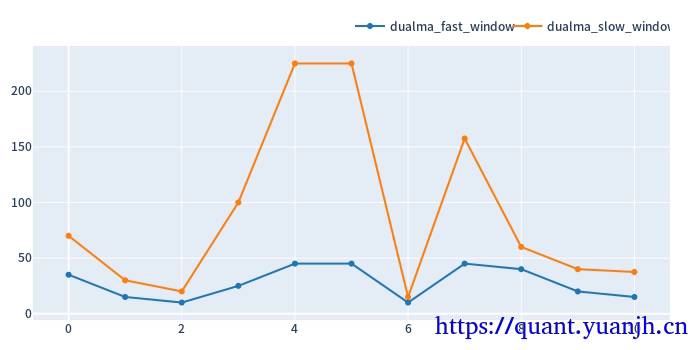
 v3<邻居权重优选法-均值>
v3<邻居权重优选法-均值>
在评估一组参数是否最佳时,并不单纯观察此参数本身是否最优,而是综合考虑参数本以及参数的邻居表现。
比如:
0.5 0.7 0.5 0.2 0.2
0.8 0.7 0.6 0.9 0.2
0.5 0.7 0.5 0.2 0.2
按照基础的最大值法,则选择0.9,但是0.9的邻居表现均不佳。
定义:新取值=原值 + (邻居的平均值)
则可以综合考虑参数本身和参数邻居点的表现。
 v4<邻居权重优选法-中位数>
v4<邻居权重优选法-中位数>
由于均值受极值影响较大,可以考虑用 median( 多个邻居),代替上面”邻居的平均值”。
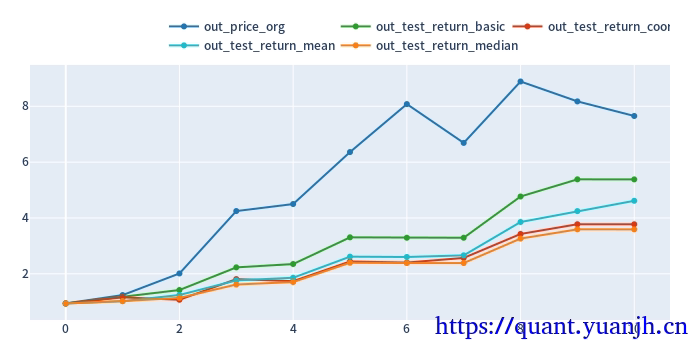
参数优选方法对应累积收益图
部分信息可能已经过时